Kafka Streams애플리케이션을 운영할때, 정확히 한 번 처리(Exactly-Once Semantics, EOS)를 보장하는 설정에서 to() 오퍼레이터를 사용해 이벤트를 발행하면, 오프셋이 한 칸씩 건너뛰는 현상이 종종 발생합니다. 처음 이런 현상을 발견했을 때는 데이터 유실이 일어난것아닌가 생각이들었습니다.
"오프셋 3, 4가 없네? 데이터가 유실된 건가?" "왜 오프셋이 연속적이지 않지?"
이런 의문을 해결하기 위해 Kafka의 트랜잭션 메커니즘과 Kafka Streams의 EOS 구현에 대해 파고들었습니다. 이 글에서는 이 현상의 원인과 내부 동작 방식을 자세히 설명하겠습니다.
오프셋이 건너뛴 이유
Kafka Streams에서 processing.guarantee를 exactly_once 또는 exactly_once_v2로 설정하고 to() 오퍼레이터를 사용하면, 종종 아래와 같은 로그 패턴을 볼 수 있습니다:
처리된 레코드: 오프셋 0
처리된 레코드: 오프셋 1
처리된 레코드: 오프셋 3 // 2가 사라짐
처리된 레코드: 오프셋 4
처리된 레코드: 오프셋 6 // 5가 사라짐
처리된 레코드: 오프셋 7얼핏 보면 데이터가 유실된 것처럼 보이지만, 사실 이것은 Kafka 트랜잭션의 내부 작동 방식 때문에 발생하는 정상적인 현상입니다.
Kafka 트랜잭션과 EOS 기본 이해하기
오프셋이 건너뛰는 현상을 이해하려면 EOS와 Kafka 트랜잭션이 내부적으로 어떻게 동작하는지 알아야 합니다. EOS는 메시지가 정확히 한 번만 처리되도록 보장하는 메커니즘입니다.
Kafka Streams에서 EOS(Exactly-Once Semantics)를 활성화하면 내부적으로 Kafka 트랜잭션이 자동으로 활성화되며, 내부적으로 Kafka 트랜잭션 API를 사용하여 입력 읽기, 상태 저장소 업데이트, 출력 쓰기, 오프셋 커밋 등을 하나의 원자적(atomic) 단위로 묶습니다. 소비자의 consumer isolation level은 read_committed 모드로 설정됩니다.
트랜잭션 시작: 명시적 마커 X

과거 Kafka 트랜잭션 설계 초기에는 트랜잭션의 시작을 알리는 명시적인 "시작 마커"를 로그에 기록하는 아이디어가 있었습니다. 하지만 현재 Kafka 구현에서는 효율성을 위해 이 시작 마커가 최적화되어 제거되었습니다. 즉, 트랜잭션이 시작될 때 별도의 마커 레코드가 데이터 토픽 로그에 남지 않습니다.
명시적인 시작 마커가 없다면 트랜잭션은 어떻게 시작될까요? 이는 프로듀서와 트랜잭션 코디네이터(Transaction Coordinator) 간의 상호작용을 통해 암시적으로 이루어집니다.
- initTransactions(): 트랜잭션 프로듀서는 먼저 initTransactions()를 호출하여 자신의 transactional.id를 트랜잭션 코디네이터에 등록합니다. 코디네이터는 이 ID를 기반으로 고유한 프로듀서 ID(PID)와 에포크(Epoch)를 할당하고, 혹시 이전에 같은 transactional.id로 완료되지 않은 트랜잭션이 있다면 중단시킵니다. 이는 프로듀서 재시작 시 이전 '좀비' 인스턴스를 차단(fencing)하고 깨끗한 상태에서 시작하도록 보장합니다.
- beginTransaction(): 개발자는 코드에서 beginTransaction()을 호출하여 논리적으로 트랜잭션을 시작합니다. 이는 프로듀서 내부 상태를 "트랜잭션 진행 중"으로 바꿉니다.
- 첫 send() 호출: beginTransaction() 후 프로듀서가 처음으로 메시지를 특정 토픽 파티션으로 보내면(send() 호출), 이때 프로듀서는 메시지와 함께 자신의 transactional.id, PID, Epoch 정보를 브로커로 전송합니다. 메시지를 받은 브로커는 이 파티션이 해당 트랜잭션에 처음 포함되는 경우, 트랜잭션 코디네이터에게 "이 파티션을 트랜잭션에 추가하라"고 알립니다. 코디네이터가 이 파티션을 트랜잭션의 일부로 등록하면서 실질적인 트랜잭션이 시작됩니다.
Kafka Streams에서 EOS를 사용하면 이 모든 과정이 자동으로 관리됩니다. 개발자는 processing.guarantee 설정만 하면 되고, Kafka Streams 라이브러리가 내부적으로 initTransactions, beginTransaction, send (.to() 호출 시), commitTransaction 등을 적절한 시점에 호출해줍니다.
트랜잭션 종료: 명시적 마커 O
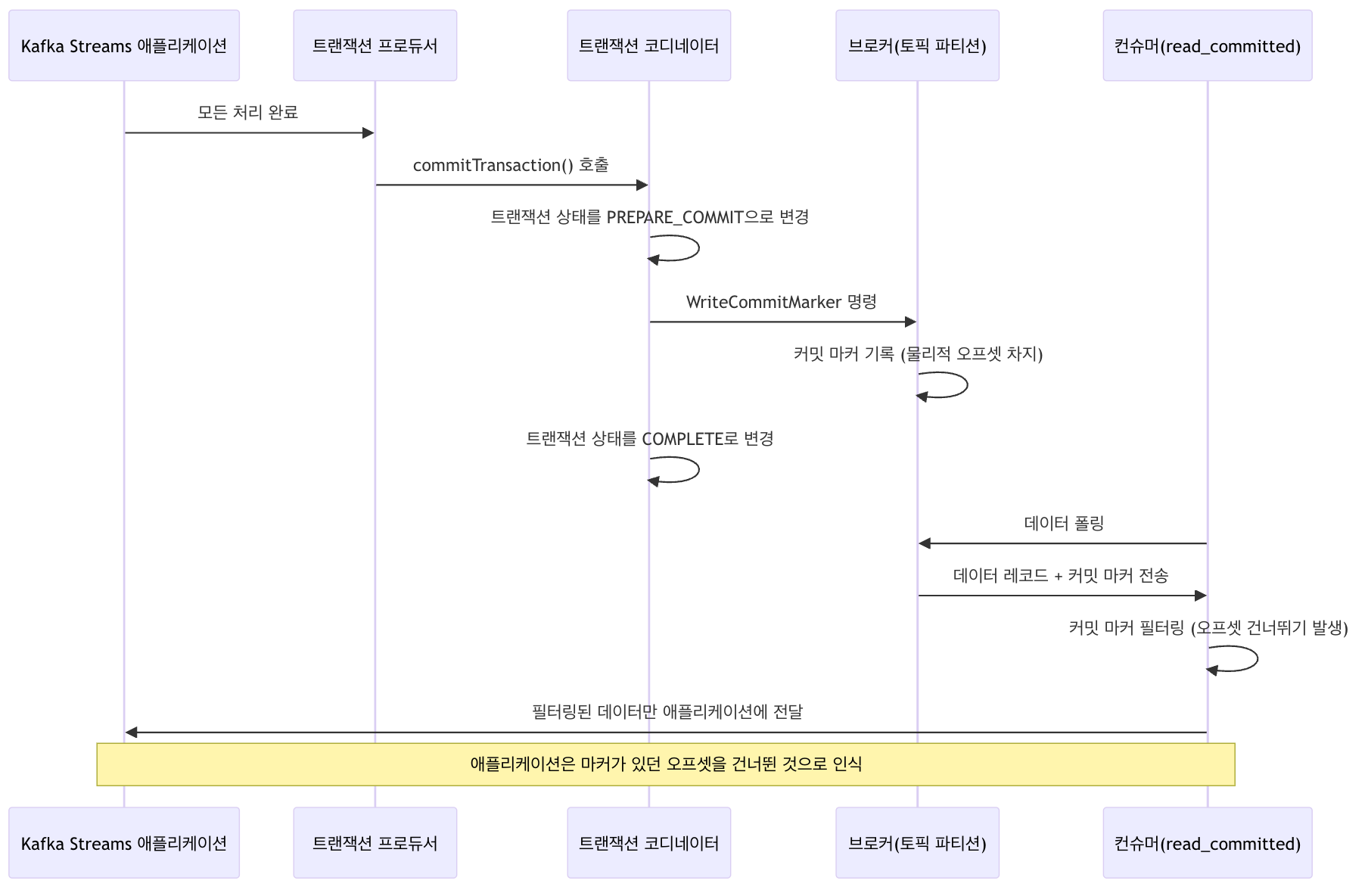
트랜잭션이 성공적으로 완료되면 커밋 마커(Commit Marker)가, 실패하여 중단되면 중단 마커(Abort Marker)가 트랜잭션에 포함된 모든 데이터 파티션 로그에 기록됩니다. 이 마커들은 트랜잭션의 최종 상태를 알려주는 중요한 역할을 합니다.
[데이터 레코드][데이터 레코드][데이터 레코드][커밋/중단 마커]이 마커는 물리적 오프셋을 차지하며, read_committed 모드의 컨슈머는 이 마커를 통해 어떤 트랜잭션이 성공적으로 커밋되었는지 판단합니다. 컨슈머 라이브러리가 마커를 받고 처리하지만, 애플리케이션 코드에는 전달하지 않기때문에, 별도로 필터링하는 로직을 구성하거나 할 필요는 없습니다.
Kafka Streams에서 오프셋 건너뛰기 발생 시나리오
실제 Kafka Streams 애플리케이션에서 오프셋 건너뛰기가 발생하는 구체적인 시나리오를 살펴보겠습니다.
시나리오 1: 정상적인 트랜잭션 커밋
오프셋 0: 데이터 레코드
오프셋 1: 데이터 레코드
오프셋 2: 데이터 레코드
오프셋 3: 트랜잭션 커밋 마커
오프셋 4: 데이터 레코드
...read_committed 격리 수준에서는 컨슈머가 오프셋 0, 1, 2, 4를 애플리케이션에 전달하고, 오프셋 3(커밋 마커)은 필터링합니다. 따라서 애플리케이션 관점에서는 오프셋 2에서 바로 4로 점프한 것처럼 보입니다.
시나리오 2: 중단된 트랜잭션
오프셋 0: 데이터 레코드 (트랜잭션 A)
오프셋 1: 데이터 레코드 (트랜잭션 A)
오프셋 2: 데이터 레코드 (트랜잭션 A)
오프셋 3: 트랜잭션 중단 마커 (트랜잭션 A 중단)
오프셋 4: 데이터 레코드 (트랜잭션 B)
...이 경우 read_committed 컨슈머는 트랜잭션 A에 속한 오프셋 0, 1, 2와 중단 마커인 오프셋 3을 모두 필터링하여 오프셋 4부터 애플리케이션에 전달합니다. 결과적으로 애플리케이션은 오프셋 0, 1, 2, 3이 모두 건너뛴 것처럼 보게 됩니다.
Kafka Streams에서 EOS와 to() 오퍼레이터
Kafka Streams에서 to() 오퍼레이터는 처리된 결과를 다른 토픽으로 보낼 때 사용합니다
// 예제 코드
KStream<String, String> inputStream = builder.stream("input-topic");
KStream<String, String> processedStream = inputStream.mapValues(value -> value.toUpperCase());
processedStream.to("output-topic"); // 여기서 to() 오퍼레이터 사용EOS가 활성화된 상태에서 to()를 사용하면, Kafka Streams는 내부적으로 다음과 같은 작업을 수행합니다:
- 각 처리 배치마다 새로운 트랜잭션을 시작합니다.
- 입력 레코드를 처리하고 상태 저장소를 업데이트합니다.
- to()를 통해 출력 레코드를 대상 토픽에 씁니다.
- 소비한 오프셋 정보를 트랜잭션에 포함시킵니다.
- 전체 과정을 하나의 트랜잭션으로 커밋합니다.
이 과정에서 커밋 마커가 생성되고, read_committed 모드의 다운스트림 컨슈머는 이를 필터링하여 오프셋 건너뛰기 현상이 발생합니다.
실제 코드로 확인하는 오프셋 건너뛰기 현상
다음은 오프셋 건너뛰기 현상을 확인할 수 있는 간단한 예제입니다
public class OffsetSkipExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "offset-skip-example");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE_V2);
// 짧은 커밋 간격을 설정하여 더 자주 트랜잭션이 발생하도록 함
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, "100");
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");
// 각 메시지의 오프셋을 로그로 출력
source.peek((key, value) -> {
// 현재 처리 중인 레코드의 메타데이터(오프셋 포함) 출력
ProcessorContext context = ((AbstractProcessor)Thread.currentThread()).context();
long offset = context.offset();
System.out.println("처리 중인 레코드 오프셋: " + offset);
})
.to("output-topic"); // to() 오퍼레이터 사용
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
// 애플리케이션 종료 로직...
}
}위 예제를 실행하고 input-topic에 여러 메시지를 보내면, 로그에서 오프셋이 연속적이지 않게 출력되는 것을 확인할 수 있습니다.
결론
Kafka Streams에서 EOS와 to() 오퍼레이터 사용 시 발생하는 오프셋 건너뛰기 현상은 트랜잭션 마커가 물리적 오프셋을 차지하고, read_committed 격리 수준에서 이를 필터링하기 때문에 발생합니다. 이는 데이터 무결성을 보장하기 위한 Kafka의 정상적인 동작이며, 데이터 유실과는 관련이 없습니다.
'Infra' 카테고리의 다른 글
| [Kafka Streams] State Store의 분산 구조와 스케일 아웃 (1) | 2024.10.27 |
|---|---|
| [Terraform] AWS Public ECR 리소스 생성 Error : no such host (0) | 2023.09.07 |
| [MySQL] 바이너리 로그의 포맷은 왜 ROW를 권장하는가? (0) | 2023.09.04 |
| [airflow] airflow-client-python 2.6.0 이하버전 airflow_client.client.exceptions.ApiTypeError: Invalid type for variable 'dag_run_timeout' (0) | 2023.05.16 |
| [Nginx] Nginx 도입기(with SSL) (2) | 2022.10.03 |