2.1 Kernels
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}CUDA에서는 C++의 함수를 지원하는데 이를 kernel이라 합니다.
kernel 은 __ global __ 이라는 specifier를 통해 정의하며 선언시 다음과 같은 형식을 따릅니다.
__global__ type fucntionName(arg1,arg2,...)상기 코드의 main함수에서 VecAdd()라는 이름의 kernel을 사용하는것을 확인 하실수 있는데 C++의 일반적인 함수들과 달리 <<<..., ...>>> 와 같은 꺽쇠 세번안에 두개의 인자가 들어갑니다.
꺽쇠안의 첫번째 인자에는 CUDA block의 개수를 두번째 인자에는 block당 CUDA thread의 개수가 들어갑니다.
2.2 Thread Hierarchy
CPU의 thread와 마찬가지로 CUDA의 thread는 작업기본 단위입니다. CUDA에서의 thread는 Block단위로 묶이고, 다시 이 Block은 Grid단위로 묶입니다.
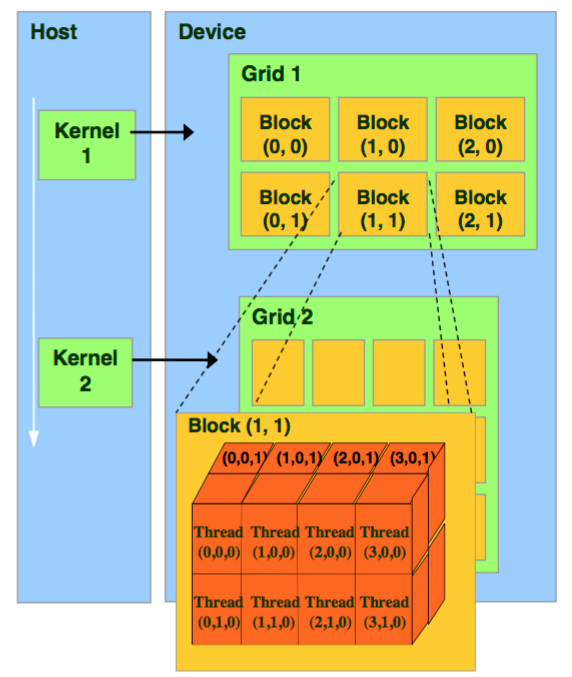
위의 그림과 같이 CUDA의 grid과 block은 1차원, 2차원 또는 3차원 세가지 구조로 정의 될수 있습니다.
다음은 행렬A,B의 합을 행렬C에 저장하는 예제 코드입니다.
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>(A, B, C);
…
}CUDA에서는 사전정의된 변수를 통해 Block과 Thread에 접근할 수 있습니다.
threadIdx.~ : block안의 thread에서 해당 thread의 인덱스를 가리킵니다.
blockIdX.~ : gird안의 block에서 해당 block의 인덱스를 가리킵니다.
blockDim.~ : block안의 thread의 개수를 가리킵니다.
이에 따라 2차원의 block을 사용할때 blockIdx.x * blockDim.x + threadIdx.x를 통해 특정 thread를 가리킬수 있습니다.
다음은 2차원의 block을 사용하여 앞선 코드와 동일한 동작을 하는 예제 코드입니다.
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]){
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main(){
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}MatAdd kernel에서 변수 i, j를 통해 thread에 접근하는 인덱스를 정의하였습니다.
main함수에서는 1차원의 block을 사용할때와 달리 numBlocks의 자료형을 dim3로 정의된것을 확인하실수 있습니다. dim3은 unsigned int 형의 구조체로 x,y,z 3개의 구조체 변수를 가집니다.
| Dimension | Block of size | Thread ID of a thread of index |
| 1 | Dx(thread per block) | x |
| 2 | Dx , Dy | x + y Dx |
| 3 | Dx , Dy , Dz | x + y Dx + z Dx Dy |
2.3 Memory Hierarchy

CUDA에서 각 thread는 local메모리를 가지고 각 Thread Block은 block과 똑같은 life time을 갖고, block내의 모든 thread가 접근할 수 있는 shared memory를 가집니다. 또 모든 thread는 어느grid, block에 속하는지 관계없이 Global memory에 접근할 수 있습니다.
'Infra' 카테고리의 다른 글
| [FPGA]Introduction of FPGA (0) | 2022.08.22 |
|---|---|
| [FPGA]Introduction of FPGA acceleration (0) | 2022.08.22 |
| [Kafka] Kafka 커맨드라인 (0) | 2022.08.22 |
| [Kafka] EC2에 Kafka서버 만들기 (0) | 2022.08.22 |
| WSL에서 mysql사용환경 만들기 (0) | 2022.08.22 |