DTO는 Data Transfer Object의 약자로 계층간 데이터를 전달하는 객체로 사용합니다.
스프링을 활용한 프로젝트에서는 주로 계층형 아키텍쳐를 설계하면서 도메인과 화면간의 의존성을 줄이기 위해 DTO를 사용하게 되는데, 이때 DTO와 Domain간의 변환을 어느 계층에서 수행할지 고민하게 됩니다.
DTO ↔ Domain 변환은 컨트롤러에서하자
DTO와 Domain의 변환을 컨트롤러에서 하게 되면 엔티티가 컨트롤러계층까지 올라온다는것을 의미합니다. 이때 DTO객체를 만들면서 의도치 않게 연관된 엔티티를 조회하면서 LazyInitializationException 혹은 N+1문제가 발생할 수 있습니다.
스프링 JPA의 open-in-view옵션을 false로 두고 JPA 지연 로딩을 사용하는 경우, controller에서 연관된 엔티티의 정보를 가져오기 위해 조회를 하게 되면 LazyInitializationException 이 발생합니다.
예를들어 상품을 조회하는 API를 설계하는 상황에서, 상품이 유저(판매자)와 연관관계를 맺고 있고, 상품의 판매자 정보를 포함한 응답을 주어야 하는 상황입니다.
상품
@Getter
@Entity
@RequiredArgsConstructor(access = AccessLevel.PROTECTED)
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Long price;
private Long quantity;
@OneToOne(fetch = FetchType.LAZY)
private User seller;
...
}
유저
@Getter
@Entity(name = "`user`")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String name;
}
상품 조회 응답
public record ProductSelectResponse(
String productName,
Long quantity,
Long price,
String sellerName
) {
public static ProductSelectResponse from(Product product) {
return new ProductSelectResponse(
product.getName(),
product.getQuantity(),
product.getPrice(),
product.getSeller().getName()
);
}
}
상품 API 컨트롤러
@RestController
@RequiredArgsConstructor
@RequestMapping("api/v1/products")
public class ProductRestController {
private final ProductService productService;
@GetMapping("{id}")
public ProductSelectResponse selectOne(
@PathVariable long id
) {
Product product = productService.findOne(id);
return ProductSelectResponse.from(product);
}
}
에러 로그
org.hibernate.LazyInitializationException: could not initialize proxy [com.example.demo.user.entity.User#1]
FetchType을 Eager로 두면 되지 않을까?
단순히 Product엔티티를 상품을 조회하는데에만 사용하고 싶다면, Eager로 두어도 됩니다. 하지만, 연관된 엔티티의 정보(User)의 정보가 불필요한 경우에도 매번 유저정보까지 한번에 조회하는 쿼리를 발생시키게 되기 때문에 가급적이면 지연로딩을 사용하는것이 좋습니다.
OSIV를 true로 두면 되지 않을까?
LazyInitializationException을 해결하기 위해 OSIV설정을 true로 둘 수 있습니다(기본값 true). OSIV를 true로 두게 되면 스프링 애플리케이션을 처음 실행할 때 다음과 같은 warn로그가 뜨는것을 확인할 수 있습니다.
JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
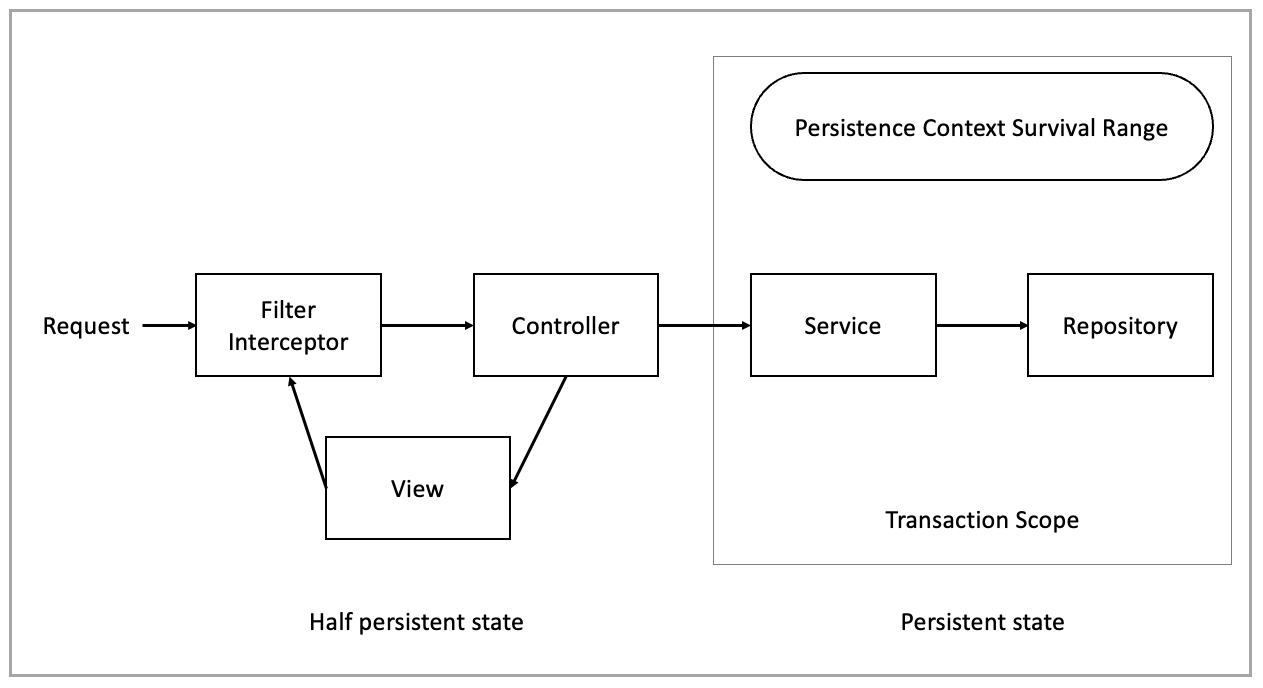
OSIV옵션은 영속성 컨텍스트의 생존범위를 컨트롤러 레이어까지 허용하는 것인데 이는 다른말로 DB와의 Connection을 컨트롤러까지 유지하고 있다는 뜻이 됩니다. 이는 성능과 확장성 측면에서 좋지않은 영향을 줍니다.
open-in-view: true

open-in-view: false
What is this spring.jpa.open-in-view=true property in Spring Boot?
DTO ↔ Domain 변환은 서비스에서하자
그렇다면 DTO ↔ Domain 변환을 서비스에서 하면 되는것 아닌가하는 생각을 하게 됩니다.
DTO와 Domain의 변환을 서비스 레이어에서 하게되면 서비스레이어 메서드의 요청과 응답은 DTO가 됩니다. 이경우 만약 JPA를 사용하고 있다면 서비스 메서드의 응답이 영속화된 엔티티가 아니라, DTO가 되기 때문에 다른 서비스 메서드가 반환된 값을 활용하고자 할 경우 JPA의 더티 체킹을 활용할 수 없게됩니다.
또한 서비스가 엔티티와 DTO모두에 의존하게 되기 때문에 서비스 메서드의 재사용성을 떨어뜨리게 됩니다.
관점의 차이
사실 이 두문제는 정답이 없는 문제입니다. 서비스 메서드의 재사용성을 위해 컨트롤러에서 DTO와 엔티티를 변환할지, 응답까지도 비즈니스 로직이라 보고 서비스레이어에서 DTO와 엔티티를 변환할지 다양한 관점에 따라 의견이 갈리는 주제입니다.
선택에 대한 트레이드오프와 관점의 차이를 잘 이해하고 설계에 맞게 유연하게 사고하는것이 필요하겠다는 생각이 들었습니다. 무조건 이렇게 하는것이 좋다더라 이렇게 하자 보다는 많이 코드를 작성해보고 고민해 보면서 자신만의 기준을 세우는것이 좋을것 같습니다.
예제 코드
'Server' 카테고리의 다른 글
| [Spring] 인터셉터와 필터로 토큰 인증, 인가 하기(with ThreadLocal) (2) | 2022.11.30 |
|---|---|
| [Junit] 병렬 테스트 환경에서의 Mockito.verify() (0) | 2022.11.02 |
| [Spring] Spring Triangle : IOC, AOP, PSA (0) | 2022.09.13 |
| [Junit] JUnit 만들어 보기 (0) | 2022.09.11 |
| [Spring] Spring vs Spring Boot (1) | 2022.08.27 |

