RAM vs Disk
DRAM과 DISK모두 저장장치의 역할을 하지만 각각이 가지고 있는 특징이 다르기 때문에 서로 다른 용도로 사용이 됩니다.
DRAM의 경우 속도가 뛰어나지만 가격이 높고, 휘발성이 있어 데이터가 영구적으로 저장되지 못한다는 특징이 있습니다. 또 바이트 단위로 데이터에 접근합니다. 때문에 CPU가까이(데이터의 이동이 잦은곳)에서 프로세서가 필요로 하는 데이터를 저장한 후 공급하는 주기억장치의 역할을 합니다.
반면 DISK의 경우 DRAM에 비해 현저하게 느린 데이터 전송속도를 가지지만, 휘발성이 없고 섹터단위로 데이터에 접근합니다. 때문에 데이터를 저장하는 보조기억장치 역할을 합니다.
RAM Disk
RAM을 주 기억 장치가 아니라 보조 기억 장치로 사용하는 개념입니다. 메모리를 기반으로 한 파일시스템이기 때문에 SSD, HDD에 비해 속도면에서 아주 우수하며 caching또는 작업 디렉토리 용도로 사용될수 있습니다. 제 개인적인 경험으로는 DRAM의 휘발성을 생각하고 RAM disk를 윈도우 인터넷 익스플로러의 임시파일 경로로 활용했던 경험이 있습니다.
Create RAM disk
Verify Memory Size
$ free -h
total used free shared buff/cache available
Mem: 6.1Gi 384Mi 5.6Gi 0.0Ki 189Mi 5.5Gi
Swap: 2.0Gi 0B 2.0Gi제경우 5.6Gi정도의 여유 메모리가 있어 이를 고려하여 램디스크로 사용할 크기를 결정 하였습니다.
ramdisk 설정
먼저 램디스크를 만들 디렉토리를 생성합니다.
$ mkdir /workspace/ramdisk아래 명령어를 통해 램 디스크를 마운트 합니다.(저는 1G만큼 할당하였습니다.)
$ sudo mount -t tmpfs -o size=1G tmpfs /workspace/ramdisk램디스크가 성공적으로 마운트 된것을 확인할 수 있습니다.
$ df -h
...
D:\ 466G 111M 466G 1% /mnt/d
tmpfs 1.0G 0 1.0G 0% /workspace/ramdisk램디스크를 사용하고 싶지 않다면 언마운트로 해제합니다.
$ umount /workspace/ramdiskRAM disk, Disk Performance evaluation
간단하게 dd유틸리티를 사용하여 속도를 테스트 합니다.
on RAM disk
$ dd if=/dev/zero of=/workspace/ramdisk/perf bs=256M count=1; rm -f /workspace/ramdisk/perf
1+0 records in
1+0 records out
268435456 bytes (268 MB, 256 MiB) copied, 0.100249 s, 2.7 GB/son disk
$ dd if=/dev/zero of=/workspace/perf bs=256M count=1; rm -f /workspace/perf
1+0 records in
1+0 records out
268435456 bytes (268 MB, 256 MiB) copied, 0.159167 s, 1.7 GB/s'CS' 카테고리의 다른 글
| [Design Pattern] Singleton Pattern (0) | 2022.08.22 |
|---|---|
| [OS] Scheduler (0) | 2022.08.22 |
| [OS] Multiprocessor Scheduling (0) | 2022.08.22 |
| [OS] Linux Kernel Structure (0) | 2022.08.22 |
| [Design Pattern] Factory Pattern (0) | 2022.08.22 |
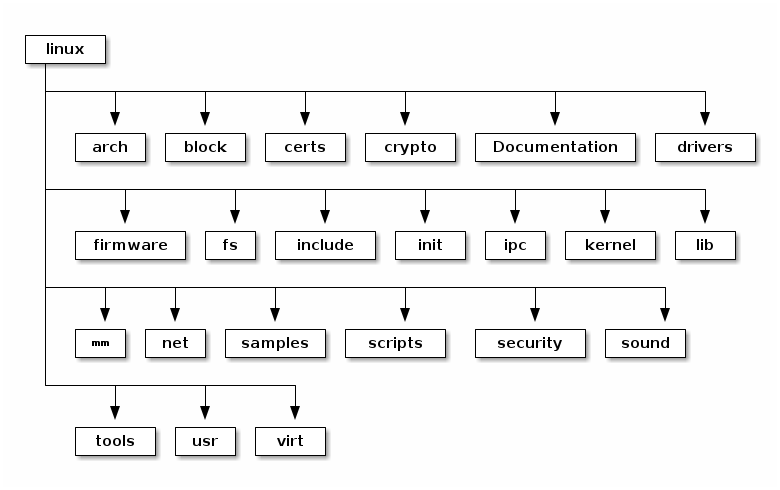
 Figure 1 : Linux Kernel
Figure 1 : Linux Kernel